Gitds-flow (Data science git work flow)
[!cue] This is a Git workflow proposed by me Daniel Guitron(aka: @danguitron) to easily have a minimalist way to work in your data science projects.
📓 Notes
After experimenting with different ways to work with Git as a Data Scientist, I realized that some commonly recommended workflows for software development, such as GitFlow, might not be the most optimal approach for data science projects, as they serve different objectives. Through discussions with a great friend and mentor Rodolfo Núñez. I device to follow his advice.
[!Note] Rodolfo Núñez Never just follow someone’s advice because they tell you to; reflect on it and see if it fits your way of working, since the most popular isn’t always the best.
That’s why today I’m proposing a workflow that I believe is optimal for Data Science—or at the very least, one that aligns well with my way of working. For the sake of conventions and simplicity, I decided to call it GitdsFlow, or gitds-flow (Git Data Science Flow).
Proposed scheme (git-flow diagram)
Everything originates from just two primary branches, which will then split into additional branches to keep the structure simple and straightforward. As Data Scientists, we don’t need an overly complex workflow, so the project will have only two permanent branches:
- main/ (production/release)
- dev/ (laboratory/test).
- Any other branches will be temporary.
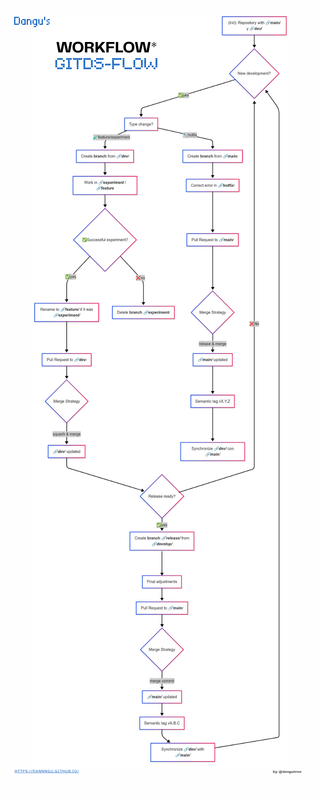
Diagram Legend
| Symbol | Meaning |
|---|---|
| Rectangle | Action or process (e.g. create branch, commit) |
| Luck | Decision point (e.g., success of the experiment?) |
| Arrows | Process flow |
| Circle (Start/End) | Flow start and restart points |
Detailed branch structure and reasons
1. Main Branches and their Relationship
A) ⚛️main/ production branch
- Origin: Root branch.
- Branches derived from it:
hotfix/*: Urgent fixes in production.release/*: Release preparation (only in very mature projects).
- What it contains:
- Production code and models.
- Versioned processed data (referenced via DVC/Git LFS).
- Only validated versions (semantic tags:
v1.0.0).
- Reason:
- You need a stable environment to reproduce results in production.
- In DS, models are critical assets: a mistake can cost millions.
B) 🧪dev/ Laboratory for experiments branch
- Origin: Root branch (sibling of
main).- Branches that branch off of it:
feature/*: New features (e.g., new model).experiment/*: Proof of concepts (PoCs).chore/*: Technical tasks (e.g., refactoring, updating libraries).
- What’s in it:
- Latest feature/experiment integrations.
- Code in a “potentially unstable” state.
- Reason:
- In DS, 80% of work is failed experiments;
devacts as a buffer before production.
- In DS, 80% of work is failed experiments;
Branch structure and commit types
1.Primary Branches
| Branch | Commit Types Allowed | Usage |
|---|---|---|
main/ |
(init), (release),(hotfix),(chore) |
|
dev/ |
experiment, feat, fix, docs, data |
2.Secondary branches
| Branch | Commit Types Allowed | Usage |
|---|---|---|
(release)/* |
chore, docs, fix |
Release preparation (versioning, final adjustments). |
feature/* |
feat, data, docs, fix |
Development of new functionalities. |
experiment/* |
experiment, data, fix |
Testing of algorithms/architectures. |
fix/* |
fix, chore |
Urgent corrections in production. |
3.Commit Types (Conventional Commits Adapted to DS)
| Type | Message Example | Applicable Branch |
|---|---|---|
feat |
feat: Add feature scaling pipeline |
feature/*, dev/ |
fix |
fix: Handle missing values in time series |
All except main/ |
data |
data: Add 2023 sales dataset |
feature/*, experiment/* |
docs |
docs: Update API reference for model training |
All |
chore |
chore: Update scikit-learn to v1.3.0 |
release/*, hotfix/* |
experiment |
experiment: Test Transformer for text classification |
experiment/* |
Examples of bad vs good practices
❌ Don’t:
1
2
3
git commit -m "Update code"
git commit -m "Fix stuff"
git commit -m "Add files"
✅ Do:
1
2
3
git commit -m "feat: Implement time series cross-validation"
git commit -m "fix: Resolve dimension mismatch in PCA"
git commit -m "data: Remove outliers from customer age column"
Cheat-sheet commands (quick guide)
| Action | Command |
|---|---|
| Create a project | cookiecutter https://github.com/drivendata/cookiecutter-data-science |
| Initialize DVC | dvc init |
| Upload data | dvc add data/raw/ && dvc push |
| Create a branch | git checkout -b feature/name |
| Make PR | git push -u origin feature/name → Create a PR in GitHub |
| Merge | git checkout dev && git merge --no-ff feature/nombre |
| Delete branch | git branch -d feature/name |
Reflection Q&A
[!faq] 🤔 Why gitds and not gitflow?
- Reason 1: In Data Science, 70% of code is disposable experiments. GitFlow is too rigid for this. GitFlow has many permanent branches (
release/,hotfix/,feature/), which is excessive for DS projects with a high rate of failed experiments. - Reason 1: Fewer branches = less complexity. You only need
main/(production) anddev/(everything else). In DS,release/is the production model, not an app version. You don’t need rigid release cycles. - Reason 3: GitFlow does not integrate tools like DVC, which are essential in DS for data versioning.
- Reason 4: PR’s(pull request) force you to review your own work, even if it’s just you.
[!faq] 🔄 When and How to Make Pull Requests (PR’s)?
What is a PR?
- It’s a request to merge one branch (e.g.,
feature/) into another (e.g.dev). - Even if you’re working alone, make PRs to review your changes before merging.
Steps for a PR
- Finish your work on the branch:
1
2
3
4
5
6
7
8
git checkout dev
git pull origin dev # Update your dev/ branch.
git checkout -b feature/new-model
# ...work on your code...
git add .
git commit -m "Train a model with Cross-Validation"
git push origin feature/new-model
- Create the PR in GitHub:
- Go to your GitHub repo > Pull Requests > New Pull Request.
- Base:
dev(branch you want to merge to). - Compare:
feature/new-model(your branch).
- Review your changes:
- Description: Explains what the PR does and how to test it.
- Example:
1
2
3
4
5
6
## What this PR does
- Adds a Random Forest model to predict sales.
- Includes 5-fold cross-validation.
## How to test it
1. Run `python train_model.py --data-path data/processed/sales.csv`
- Merge the PR:
- If everything is fine, click “Merge pull request”.
- Use “Squash and merge” if there are many small commits (it simplifies the history).
[!faq] 🔄 When to Make a PR?
- Whenever you want to merge into
devormain. - Examples:
- You completed a successful experiment and want to integrate it into
dev. - You fixed a bug in
devand want to bring it intomain
- You completed a successful experiment and want to integrate it into